
.png)
LI Test
LI Test
TLDR: Today, we are launching our Research API, a new deep search offering that ranks #1 on DeepSearchQA with the highest publicly reported 83.67% accuracy and 93.16% F1 score. Our scalable research compute capabilities enable us to push the frontier of accuracy and latency across both simple and complicated tasks, as shown by our top performance across industry benchmarks ranging from SimpleQA to DeepSearchQA.
Our Approach
After significant experimentation and technical deep dives, we designed a robust harness to minimize human-steering while maximizing agent autonomy. Our harness drives the most powerful models to effectively navigate problems of varying complexities. In tandem, we ensure that the data that we retrieve and extract is of the highest quality and relevancy. This approach powers our Research API, achieving state-of-the-art results.
How does this play out in the real world? The research path our Research API takes varies significantly based on the type of query. A mathematics question follows a different trajectory than a compliance question or a competitive landscape analysis.
The robust harness, plus super-charged tooling has been designed with extreme thoughtfulness on what data to include, ensuring that Research performs well.
Our Search API as the Core Primitive
We have heavily invested in mapping and understanding public web content via our Search, Contents, and Live News APIs. Research is designed to leverage these core APIs as tools in the best way possible. This cuts down on wasted calls and gives the model cleaner inputs, leading to increased efficiency.
Research works to ensure sources retrieved are appropriate for the task at hand, in terms of freshness, diversity, and other core query-specific qualities across its depth-focused exploration.
Managing Context
Deep research generates far more information than any frontier LLM's context window can hold. We built context-masking and compaction strategies that let Research operate well beyond those limits, maintaining coherent reasoning across hundreds or thousands of turns without losing track of what it found, what it verified, and what is still unresolved.
Your Constraints and Choices
The Research API receives a budget based on the research_effort tier you choose—lite, standard, deep, exhaustive, or frontier. Agent scaling is the primary mechanism that allows us to push the frontier across cost, accuracy, and latency. The system plans its approach around your budget and allocates effort where required to ensure all constraints are met. As an example, the system will spend more time verifying high-stakes, ambiguous claims versus clear, well-sourced facts.
For particular long-horizon deep research tasks, Research will run more than 1000 reasoning turns and expend up to 10 million tokens on a single query. This design is what makes a wide range of latency and accuracy tradeoffs possible.
Pushing the Frontier
To showcase our Research API’s capabilities, we benchmarked across a breadth of industry standard search and research benchmarks, including SimpleQA, FRAMES, BrowseComp, and DeepSearchQA. These benchmarks include everything from simple, single-hop questions to more complicated, multi-hop questions, highlighting the flexibility of our Research API.
SimpleQA (OpenAI)
Our deep and exhaustive research efforts achieve the highest accuracy on SimpleQA, with lower latency than other APIs in the same accuracy range.
SimpleQA is a 4,326-question benchmark of short, fact-seeking questions designed to test factual accuracy on single-hop lookups.
.jpg)
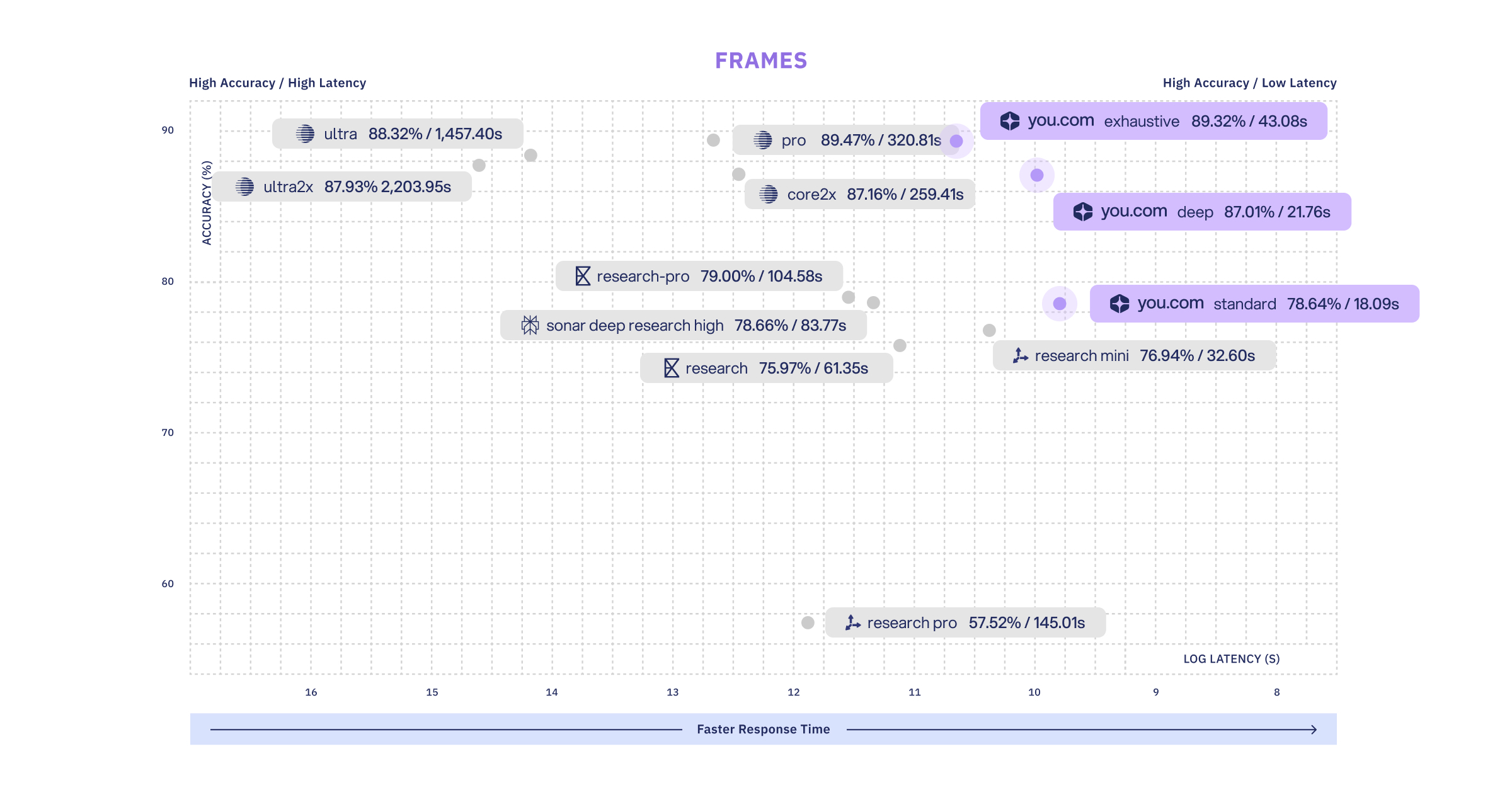
FRAMES (Google)
Our exhaustive research effort is in the highest accuracy range, with latency at 1/7th of providers in the same accuracy range.
FRAMES is an 824-question benchmark testing factuality, retrieval accuracy, and multi-step reasoning across questions that require synthesizing information from multiple sources.
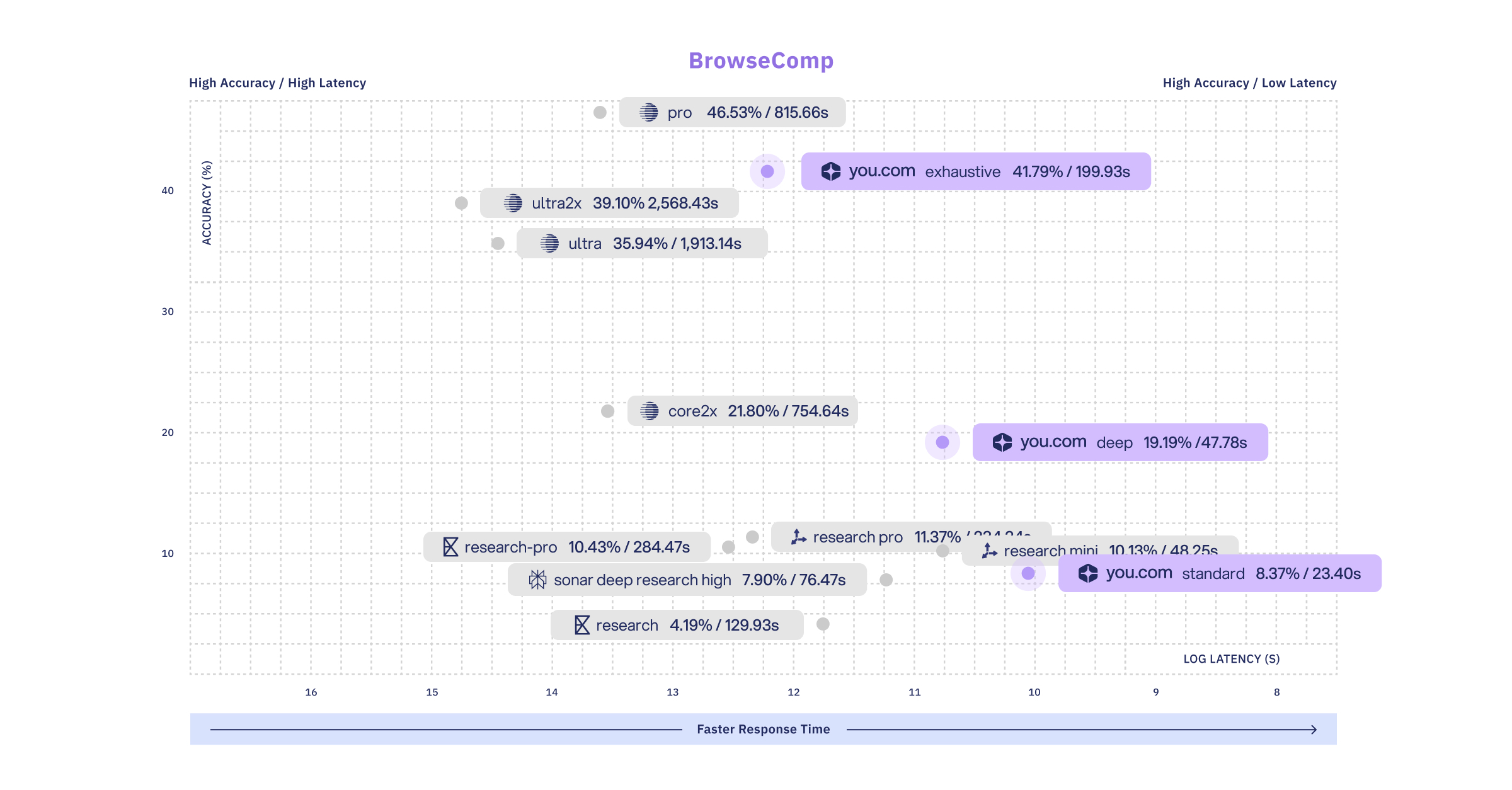
BrowseComp (OpenAI)
Our exhaustive research effort is the second highest accuracy, with latency at 1/4th of the offering with the highest accuracy.
BrowseComp is a 1,266-question benchmark evaluating whether a system can find specific, verifiable facts that require navigating and extracting information across multiple web pages.
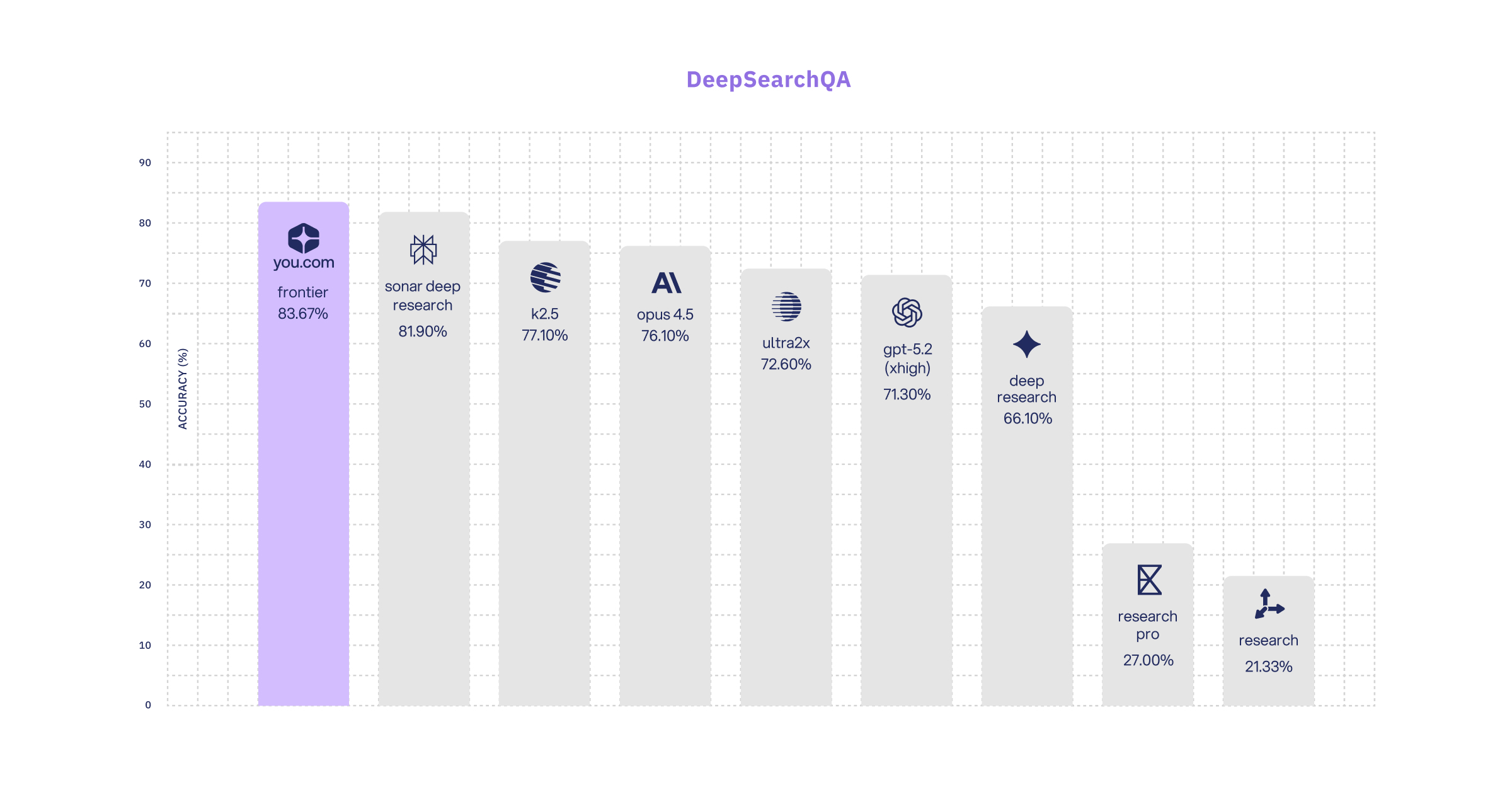
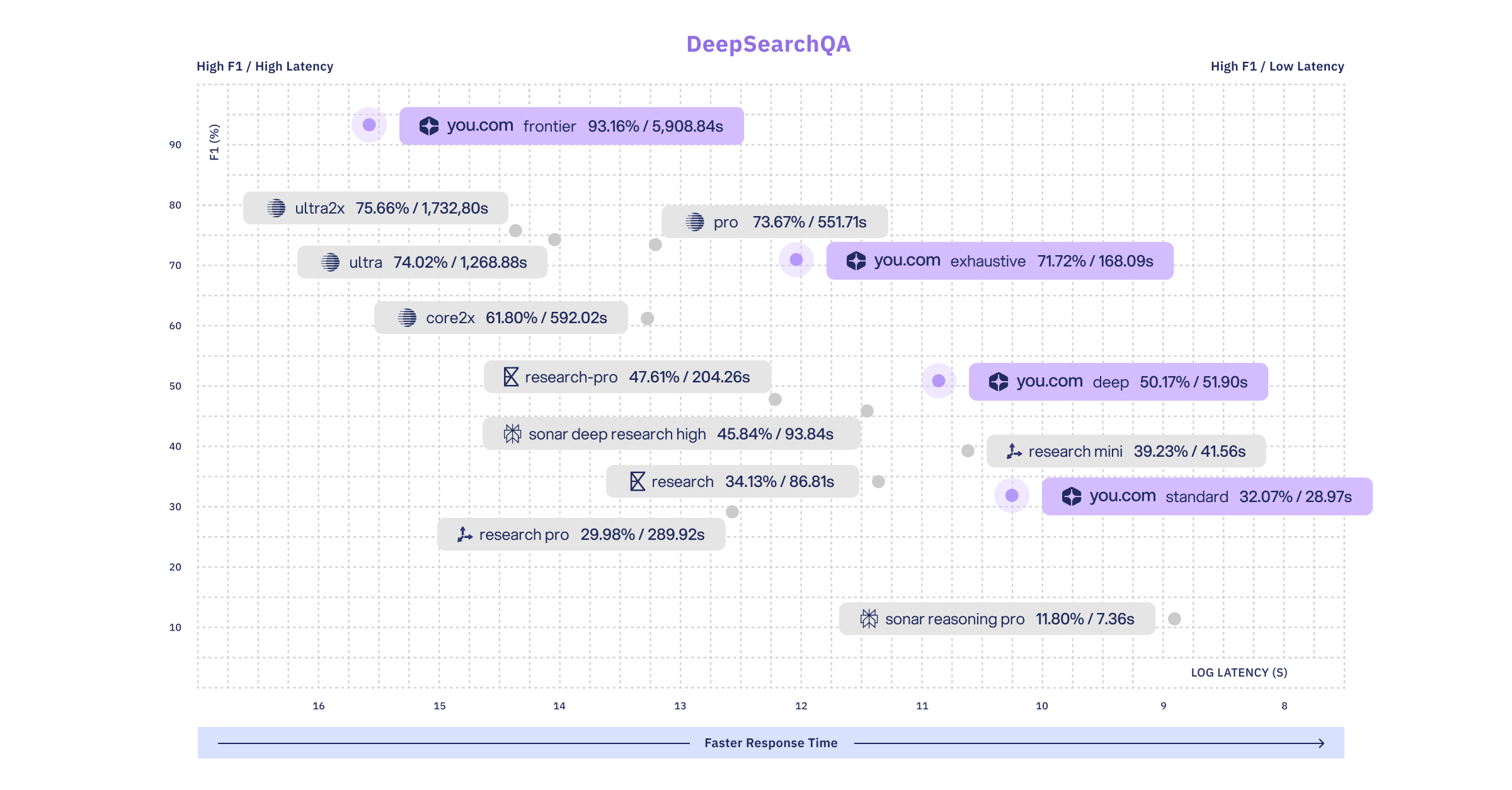
DeepSearchQA (Google DeepMind)
Our frontier research effort achieves the highest accuracy and F1 scores in the industry.
To obtain F1 and latency scores across benchmarks (which are not often publicly reported), we ran various research APIs on the full DeepSearchQA set. We also report the top accuracies reported in the industry as well for comparison purposes.
DeepSearchQA is a 900-prompt dataset evaluating agents on difficult multi-step information-seeking tasks across 17 fields.
Research API Details
To provide developers with flexibility based on accuracy, cost, and latency requirements, Research offers a research_effort parameter, which controls how much research compute is utilized to generate a response.
For the query, “Which global cities improved air quality the most over the past 10 years, and what measurable actions contributed?” we show the variation between the standard vs exhaustive research effort here:
Here are example responses from the Research API (which are abridged for display purposes):
In both instances, the response includes an answer with citations, along with source attribution and full citations. The higher research_effort, exhaustive, call has more effort extended to identify additional cities, more granular data, and completes more thorough cross-referencing to ensure validity.
The structure of the response is simple and prioritizes ease of use for downstream workflows. In both instances, the response includes an answer with citations, along with source attribution and full citations. The higher research_effort, exhaustive, call has more effort extended to identify additional cities, more granular data, and completes more thorough cross-referencing to ensure validity.
The structure of the response is simple and prioritizes ease of use for downstream workflows.
Pricing
Pricing is fixed per tier.
Getting Started
1. Sign up and get your API key. No credit card required for testing
2. Full documentation: docs.you.com/api-reference/research/v1-research
3. Full eval code coming soon. We want you to run it.
Featured resources.
.webp)
Paying 10x More After Google’s num=100 Change? Migrate to You.com in Under 10 Minutes
September 18, 2025
Blog

September 2025 API Roundup: Introducing Express & Contents APIs
September 16, 2025
Blog

You.com vs. Microsoft Copilot: How They Compare for Enterprise Teams
September 10, 2025
Blog
All resources.
Browse our complete collection of tools, guides, and expert insights — helping your team turn AI into ROI.

Nvidia, DuckDuckGo Back AI Search Startup You.com
September 4, 2024
News & Press

With $50 million in new funding, You.com thinks its AI can beat Google on hard questions
September 4, 2024
News & Press

AI Agents From You.Com Aim To Boost Enterprise Productivity
September 4, 2024
News & Press

AI startup You.com raises $50 million, predicts ‘more AI agents than people’ by 2025
September 4, 2024
News & Press

You.com raises $50 million to make knowledge workers more productive
September 4, 2024
News & Press

You.com wants to be your AI search engine for complex work queries
August 22, 2024
News & Press

Access the most powerful AI models in one place on you.com
July 29, 2024
Blog