September 2025 API Roundup: Introducing Express & Contents APIs


As we wrap up September, we’re excited to announce two major additions to our developer platform: the Express and Contents APIs. These new APIs are designed to make it easier than ever to build web-aware applications, power retrieval-augmented generation (RAG) pipelines, and create smarter agents—all with less overhead and more reliability.
Today, we’re announcing:
- Express API: Fast, web-grounded answer API with “search + answer” all in one call—purpose-built for agents and apps that need fresh facts without orchestration overhead.
- Contents API: Use this API to gather reliable page text and metadata without building a crawler, a parser, and a sanitizer, reducing hallucinations by feeding models real, current source material..
What’s New: Express API & Contents API
Express API: Fast, Web-Grounded Answers in One Call
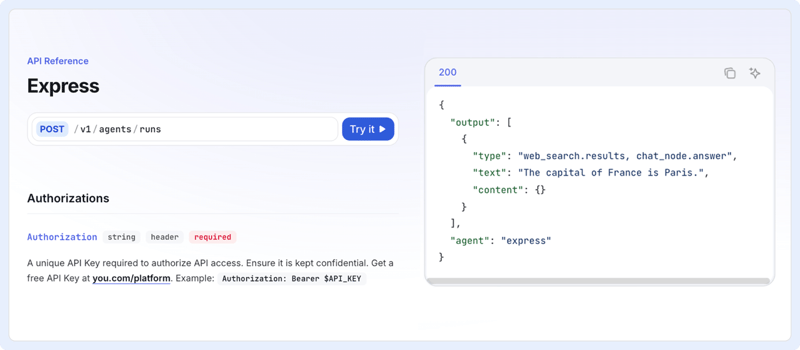
The Express API is your new fast lane for getting web-grounded answers. Given models have knowledge cutoffs, reliable live search keeps answers current and reduces hallucinations. Express packages “search + answer” in a single API call: you send a query, and get back an LLM-generated response with inline citations, plus a transparent list of the web results used to ground the answer. No need to orchestrate multiple services or handle complex pipelines.
This API is purpose-built for agents and apps that need fresh, factual information without the overhead—making it a modern, developer-first solution for quick, reliable insights.
Key features
- LLM answer with inline citations
- Array of web results used for grounding and transparency
- Simple, single-shot endpoint for RAG-style use
- Designed to reduce hallucinations by always grounding answers in live search data
Potential use cases
- LLM agents that need quick, grounded answers
- RAG pipelines where freshness and accuracy matter
- Research, market intelligence, and monitoring tools that require quick, up-to-date information
How it works:Send a query, receive a JSON response with:
- answer: The grounded answer with inline citations
- citations: Array of {title, url, snippet}
- results: Array of web results for transparency and rendering
Learn more and see example requests in the Express API documentation.
Contents API: Fetch, Parse, and Return Any Web Page Content
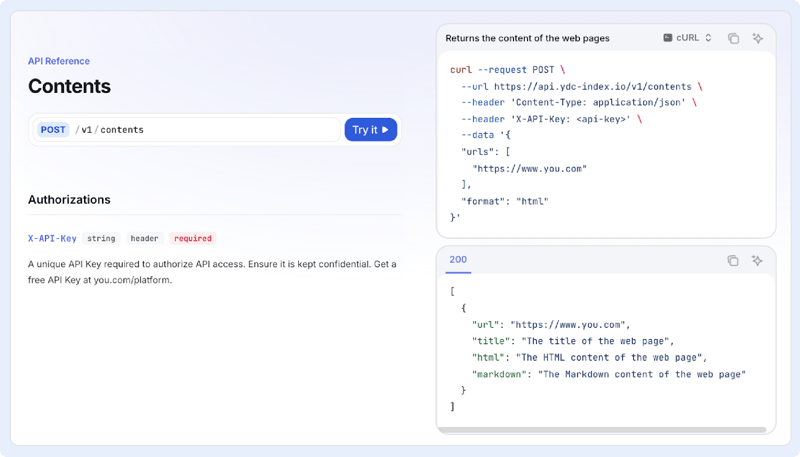
If you’re powering RAG, agents, or any web-aware feature, you need clean, structured page content on demand. The Contents API gives you reliable page text and metadata without building a crawler, a parser, and a sanitizer, helping you reduce hallucinations by feeding models real, current source material. It returns the page’s Markdown, HTML, and key metadata—delivered as clean, structured JSON, ready to slot into your workflow. No need to build your own crawler, parser, or sanitizer: this API gives you real-time, reliable page text, helping you fuel RAG, agent pipelines, or web-aware features with current source material.
This API is purpose-built for agents and apps that need fresh, factual information without the overhead—making it a modern, developer-first solution for quick, reliable insights.
Key features
- Pulls clean Markdown and/or HTML from any URL
- Returns key metadata (title, URL, etc.)
- Works with single URLs or batches
- Designed for easy integration into frameworks like LangChain
Potential use cases
- Agent Builders: Convert web pages into model-ready inputs for smarter, context-aware AI.
- RAG Pipelines: Fetch clean, structured content easily for chunking and retrieval.
- Research and Monitoring Teams: Extract and process content at scale, with zero scraping headaches.
How it works:
Send a single URL or a list of URLs, and get back:
- url, title, html, and markdown for each page
You can also use the Contents API via the Search API by specifying livecrawl parameters, making it even easier to integrate into your workflow.
See the Contents API documentation for details.
How You Can Get Started
Ready to build?
Create your API key, explore the Express API and Contents API documentation, and start integrating into your apps today.
Subscribe and start building today!
Stay tuned for more updates as we continue to expand our API platform and empower developers to build the next generation of AI applications!
LI Test
LI Test
Share Article:
Related resources.
.png)
How APIs Became the Connective Tissue of LLMs
May 20, 2026
Blog
.png)
Context Rot Is Quietly Breaking Your API Integrations
May 1, 2026
Blog

What Is a SERP API? Architecture, Limitations, and Why the Market Is Shifting
April 30, 2026
Blog
.png)
When a Simple Search Isn't Enough: Building With the Research API
March 23, 2026
Blog
.jpg)