Simple Abstractions, Dense Payloads: Tool Design for Agentic Search


LI Test
LI Test
Part II of a series on the design of the You.com Research API. Read part I here.
Our previous article described how single-agent inference scaling at extreme token budgets—up to 10M tokens and 1,000 turns—unlocks state-of-the-art performance on DeepSearchQA.
This article, however, goes deeper into the design of the tool layer that the agent utilizes to efficiently gather information on every turn.
Two principles shaped it:
1. Use Simple Tool Abstractions
Simple tool schemas let the model spend its budget on reasoning rather than on learning a custom interface. Every extra parameter is one more decision the model has to make on every call (and one more chance to make the wrong one). Over-engineered schemas burn context tokens on tool semantics that should be spent on the problem.
2. Design for Token Efficiency
Context space in the main agent is precious. It's where the model holds the question, the evidence gathered so far, and the reasoning that ties them together. If not managed properly at long horizons, models may succumb to context rot.
Flooding the context with uncompressed tool outputs creates a “needle in a haystack” problem, making it difficult for the agent to reliably retrieve crucial facts later on. Keeping the tool output token efficient also reduces the frequency of memory management interventions which may degrade cost efficiency by lowering cache hit rates.
The Agentic Harness
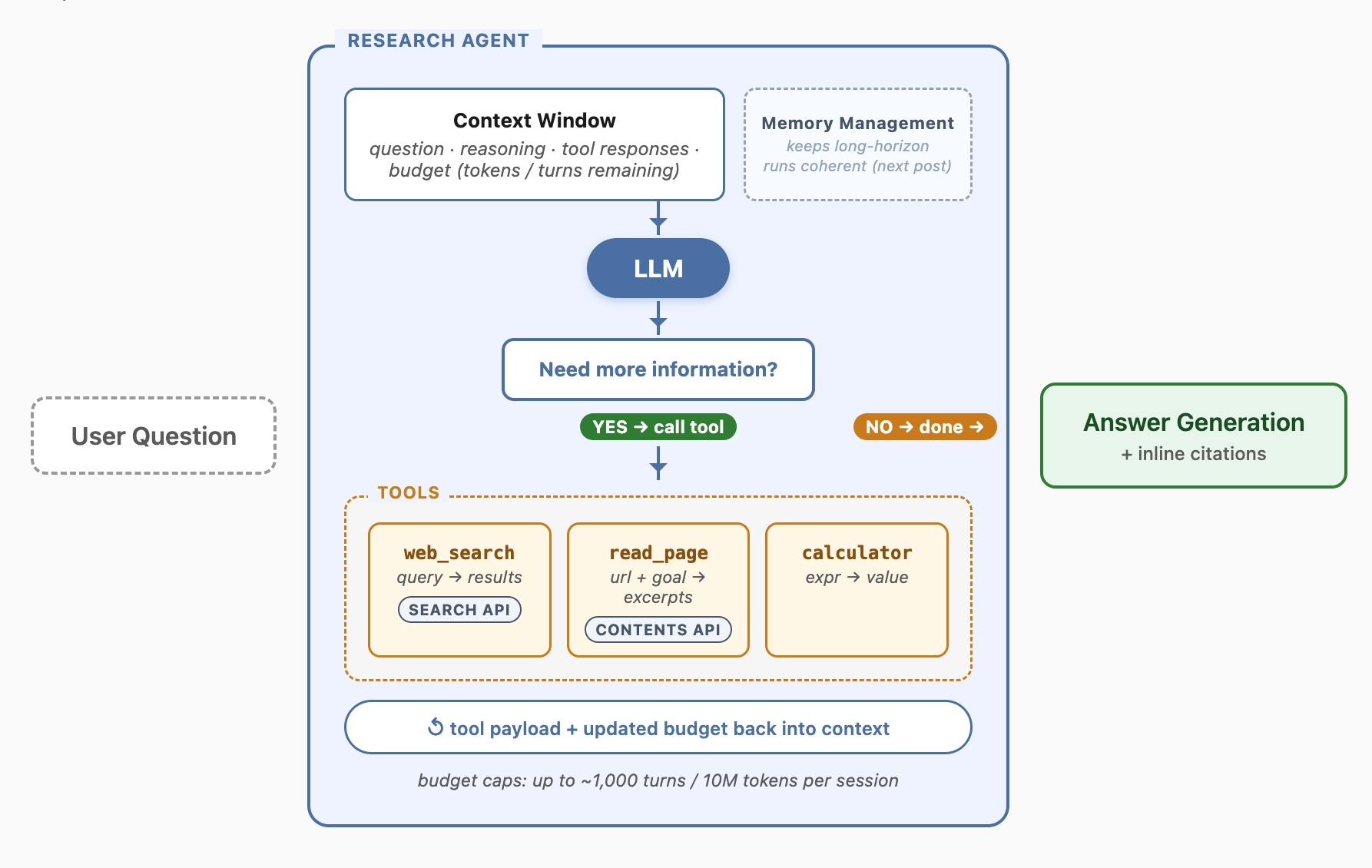
Before getting into tool design, it's worth grounding the picture of how the agent actually runs. Our research agent operates in a tool-interleaved reasoning loop—a ReAct-style harness where the model alternates between thinking, calling a tool, and incorporating the tool's response into the next round of thinking.
On every turn, the model sees the full trajectory: the original question, its prior reasoning, every tool response, and budget blocks indicating tokens consumed and turns remaining. With that context in hand, it decides one of two things: either issue another tool call to gather more evidence, or stop and write the final answer. The model itself drives the loop, turn after turn, until it has enough to answer or its budget runs out.
The Primitives: Information Gathering Tools
Our agent gathers information through two primary tools:
The web_search tool, powered by our Search API, allows the agent to retrieve a list of relevant results for the agent. When the agent needs more depth from a specific search result, it can use the read_page tool, powered by our Contents API, to read and extract excerpts relevant to its current objective.
We deliberately kept the tool interface simple so the agent has fewer parameters to choose, and fewer chances to choose them incorrectly. When callers need more control over the sources web_search draws from, the Research API exposes a source_control field at the request level, reducing the need for the agent to manage complex search operators.
While web_search and read_page connect the agent to external knowledge, we also equip it for internal logic. We expose a calculator tool for arithmetic and date operations (such as calculating the days between two dates). Doing math or date interval logic in-context is both wasteful and error-prone: the agent burns tokens on intermediate steps, and frontier models still make arithmetic mistakes on long expressions.
A dedicated tool keeps numerical and temporal work cheap and correct, freeing the agent's context for the parts of the problem that actually require reasoning.
Read Page: Goal-Conditioned Extraction
A goalless implementation of read_page(url) typically resorts to returning paginated chunks. This violates the principle of token efficiency and actively introduces noise, as relevant context is often arbitrarily severed across chunk boundaries. Worse, it forces the main agent to spend its compute managing a tedious pagination loop rather than focusing on higher-order reasoning.
To cut through this noise, we took inspiration from the Tongyi Deep Research work, which effectively used goal-conditioned page reading to scale deep research agents. Instead of returning the page, it returns what the page contains that's relevant to the agent's stated goal.
Behind the scenes, read_page fetches the url and runs a small extraction step.An extractor reads the parsed page conditioned on the goal and returns only the relevant excerpts for greater token efficiency.
Right-Sizing the Extractor
Pages aren't all the same shape. A 5KB article and a 500KB SEC filing pdf both arrive through read_page, and the right extraction strategy for each is different. We route extraction by length and format—small pages go to a fast extractor, large pages go to one designed for long-context reading, and specific file types can be routed to specialized extractors.
Instead of paying the latency and token overhead of a long-context model on every visit, this dynamic routing matches the extraction strategy directly to the document's complexity.
Compact Link Encoding & Compressing the Search Frontier
To further reduce extraction cost, we addressed one source of token sink inside a typical webpage: the links. We borrowed an encoding from OpenAI's gpt-oss simple-browser tool.
Replace each link in the page text with a short bracketed marker carrying just an ID, the anchor text, and (for cross-domain links) the domain:
Abstracting away raw URLs serves two critical purposes. First, it allows LLM based extractors to focus on the core information rather than parsing the token-heavy noise of link-dense pages like Wikipedia. Second, embedding these link markers directly within the prose naturally enables follow-up navigations. If a page doesn't fully satisfy the goal but points to a better source, the extractor returns a short list of promising integer IDs, which we then resolve back into real URLs.
Citation System
A research agent that produces uncited answers isn't useful. Users need to verify claims; downstream systems need to attribute them. Citation has to be woven into the tool responses themselves. Every snippet returned by web_search and every excerpt returned by read_page is registered against its source URL and prefixed with a unique citation marker.
The agent treats the marker as part of the excerpt—when it writes its answer, it quotes the excerpt by emitting the marker as an inline citation. We resolve those markers back to URLs, sources, and exact passages during response-assembly. By using these compact markers instead of full URLs or complex mappings, the system avoids bloating the working context and minimizes the consumption of output tokens during answer generation or reasoning.
What This Adds Up To
The agent calls a few familiar functions—web_search, read_page, and calculator—and receives dense and fully citable payloads in return. Because the interface is frictionless and already second nature, the model can dedicate its entire inference budget to the research itself rather than wrestling with the harness.
In the next post we'll talk about what happens when, despite all of this, the working context still fills up over dozens of turns—and how context compaction keeps long traces coherent without losing the thread of the investigation.
Featured resources.
.webp)
Paying 10x More After Google’s num=100 Change? Migrate to You.com in Under 10 Minutes
September 18, 2025
Blog

September 2025 API Roundup: Introducing Express & Contents APIs
September 16, 2025
Blog

You.com vs. Microsoft Copilot: How They Compare for Enterprise Teams
September 10, 2025
Blog
All resources.
Browse our complete collection of tools, guides, and expert insights — helping your team turn AI into ROI.

The AI Governance Problem: Why Web Search APIs Are the Missing Layer
April 20, 2026
Blog

Guide: Why API Latency Alone Is a Misleading Metric
April 15, 2026
Guides

Governing AI Isn't Optional Anymore—and the Fix Starts at the Infrastructure Layer
April 14, 2026
News & Press
.png)
Best Web Search APIs for AI Agents: What to Test Before You Commit
April 13, 2026
Blog

Building a Recursive Agent-Improvement Pipeline
April 9, 2026
Blog

Why API Latency Alone Is a Misleading Metric
April 7, 2026
Blog

What Does It Actually Take to Build AI That Works? Richard Socher Has Some Answers
April 2, 2026
News & Press
What Is Retrieval Augmented Generation (RAG)?
April 1, 2026
Blog