Search API for the Agentic Era: Optimize Accuracy, Freshness, Latency & Cost

Introduction
AI agents are reshaping how people access information. Unlike traditional search engines, agents aren't browsing the web using keywords, skimming snippets, or blue links. They're making intelligent tool calls that require structured, high-signal, context-aware passages to reason and act effectively.
This 2025 API Benchmarking Report rigorously compares You.com’s Search API with leading alternatives using benchmarks across the below criteria, which matter most for AI application development:
- Accuracy
- Freshness
- Latency
- Cost
By standardizing answer synthesis and grading across all providers, the report isolates the impact of the Search API itself, uncovering which solutions truly enable retrieval workflows that are robust for both factual and time-sensitive queries.
Need lightning-fast fact verification? You.com’s standard search endpoint delivers precise answers in under 445ms. Building a research agent that needs a comprehensive analysis? You.com’s research endpoint prioritizes depth over speed. Additionally, across industry standard benchmarks, You.com consistently delivers superior accuracy, lower latency, and better cost efficiency. Same API, different optimization profiles, because your agent's task complexity shouldn't be constrained by your search provider's limitations.
For developers building next-generation AI applications, this means no more choosing between fast-but-shallow or slow-but-thorough. You.com’s Search API is built for the agent era, delivering best-in-class performance with endpoint flexibility that lets your agent be both lightning-quick when it needs to be, and comprehensively thorough when the task demands it.
Methodology
We benchmarked You.com’s Search API against several alternatives across four key dimensions: 1) Accuracy, 2) Freshness, 3) Latency, and 4) Cost.
- Accuracy: How well the retrieved content supports correct answers
- Freshness: Ability to answer questions about recent events
- Latency: How quickly results are returned
- Cost: Cost per thousand (CPM)
While most search benchmarks only focus on accuracy and latency, we evaluated search quality through the lens of how well it enhances LLM-based question-answering: how well do APIs perform when generating LLM-based content?
To ensure fair comparisons, we standardized everything downstream of the retrieval process.
- Search results from each provider were collected for the same set of queries.
- Answer synthesis was done using GPT-4.0 mini, so every provider’s results were processed by the same model.
- Answer evaluation used GPT-4.1 with temperature set to 0, which graded correctness against ground truth answers.
This method isolates search quality and removes variability introduced by the answer-generation stage. It asks a simple question: if all else is held constant, which search engine provides the most useful raw results for downstream LLM pipelines?
Benchmark Criteria & Evaluation
We selected three complementary benchmarks to provide a balanced and rigorous evaluation set expected by enterprise customers.
- SimpleQA dataset: In this benchmark, which tests for accuracy, an LLM agent answers factual, trivia-style questions using search results from each provider. We also examined latency and cost across three other providers.
- FreshQA: This benchmark has newer and up-to-date questions, which tests for freshness. This effectively tests a model’s ability to reason about recent facts, adapt to changing contexts, and avoid relying on outdated data.
- MS Marco: This benchmark tests for latency, as well as quality, relevance, and confidence with a robust dataset of over 10,000 queries.
SimpleQA Dataset & Findings
Methods: An LLM agent (GPT4o-mini) was tasked with answering factual, trivia-style questions (the SimpleQA dataset) using search results from each provider. To judge correctness, we employed another LLM (GPT4.1), using OpenAI’s official SimpleQA grading prompt, which scores how often the agent’s final output matches the expected answer.
This approach captures a critical dimension: how effectively does the Search API improve downstream agent reasoning and synthesis workflows?
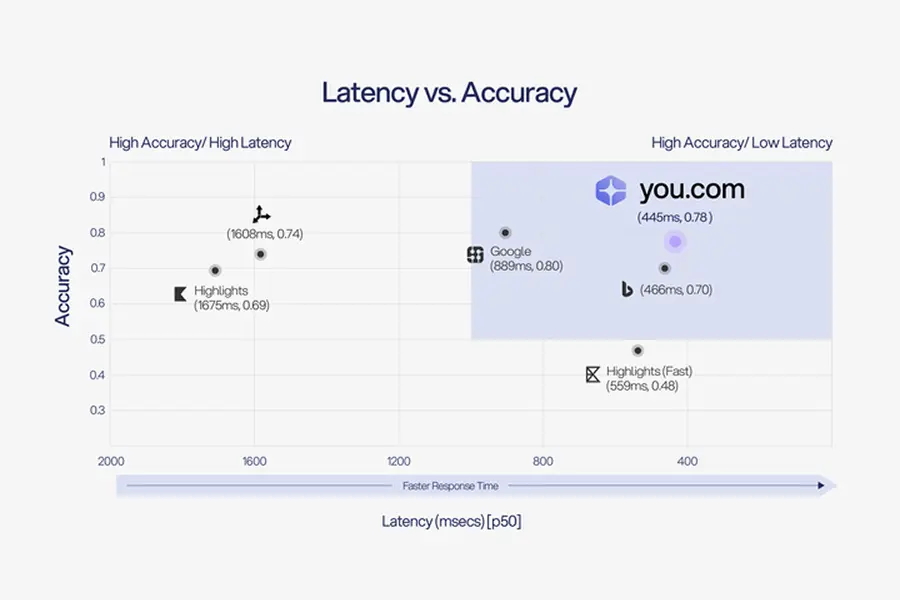
Findings: You.com incorporates a high quality of our retrieval in isolation and has effectiveness in real-world agent workflows, especially in tool-calling pipelines where tight response loops matter. For SimpleQA-style factual questions, You.com achieved 77.84% answer accuracy (95% CI: 76.60% - 79.08%) using shorter, more relevant snippets delivered in 445ms (p50).
The quadrant below, highlighted in blue (high accuracy and low latency), is the optimal position for SimpleQA.
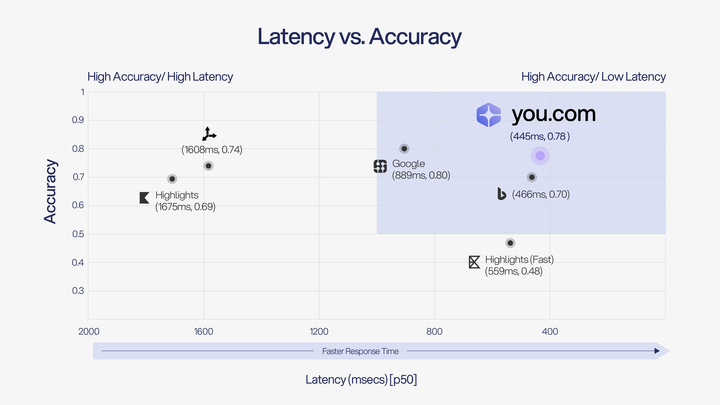
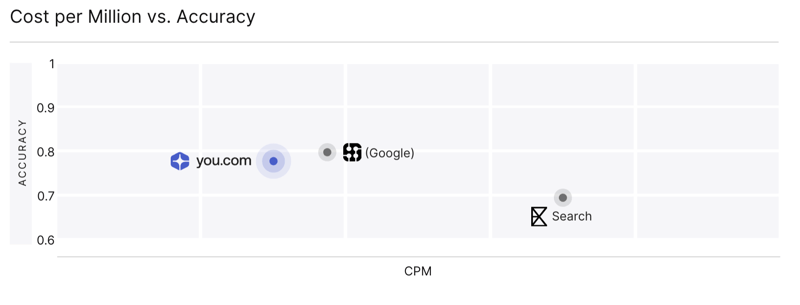
While the SimpleQA results demonstrate You.com’s performance in one specific scenario, real agent applications demand much more versatility. Furthermore, as shown below, You.com delivers the highest level of accuracy at the lowest cost.
FreshQA Dataset & Findings
Methods: In this test, we are using GPT-4.1 in order to answer 500 contemporary questions. These questions come from the July 28th, 2025 FreshQA dataset, which was the most up-to-date dataset at the time of testing. We chose not to rewrite queries and to use FreshQA questions as they were, as we wanted to understand how the search engines handle the vocabulary mismatches. In this test, we score on Freshness (recency of results), F1 score (a measure of both precision and recall), and semantic accuracy (ie: the answer is not just factually correct but aligned to the user’s intent when asking the question).
Findings:
- Freshness or the ability to answer questions about recent events: On average, You.com can answer significantly more questions compared to alternatives, only returning “Can’t answer question” in just 1 out of 5 questions, while others couldn’t answer over 50% of the questions.
- Precision and recall: A F1-score is the average of precision and recall - a lower score means that either precision or recall is low. You.com’s Search API’s F1-score is the highest among its peers at 0.44.
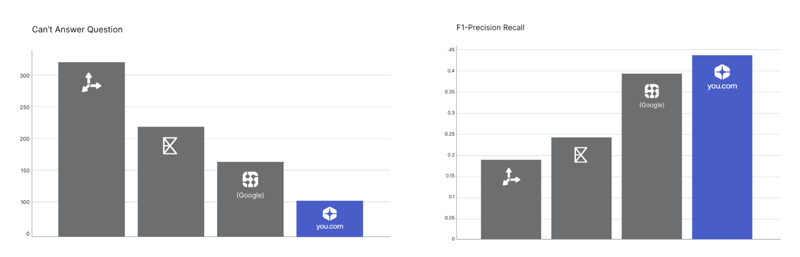
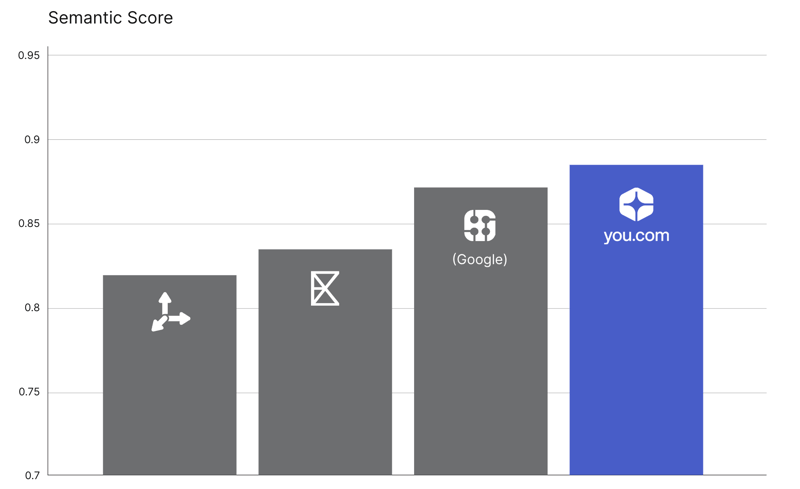
- Semantic score: This indicates that You.com excels at returning results that are not just factually correct, but also contextually aligned with user intent.
MS Marco Dataset & Findings
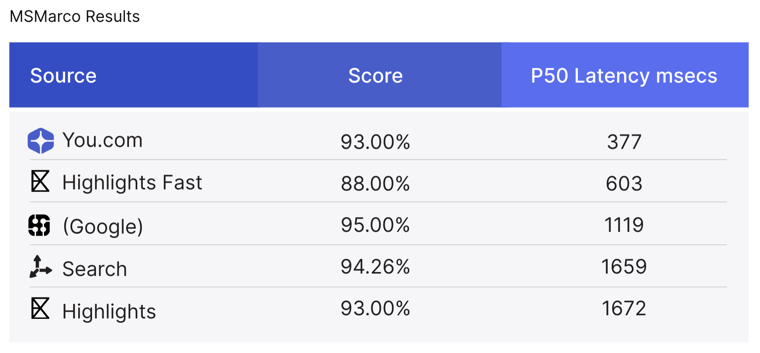
Methods: The third and final dataset was the MS MARCO dataset (10,000 queries), widely recognized for its diversity of user queries and intent. This dataset emphasizes real user queries, many of which are ambiguous, verbose, or unstructured, making it an excellent testbed for search robustness. For this evaluation, we focused on passage retrieval quality by measuring how well search engines return relevant, high-quality, and confident results for MS MARCO queries. Again, no query rewriting or prompt engineering was applied. Queries were used as-is to assess how each engine handles vocabulary mismatches, ambiguity, and query intent inference. The evaluation was performed by GPT-4.1 for relevance, quality, content reliability, and overall usefulness.
Each result was evaluated using a custom scoring rubric detailed below.
Overall Score: A weighted aggregation of the 3 metrics below: (0-1 scale)
- Query Relevance: How well the results directly answer or address the user's query
- Result Quality: Depth, accuracy, and overall usefulness of the returned content
- Confidence: How confident the evaluator is in the assessment (higher when results are clear, reputable, and consistent)
Latency: Search query latency as measured by wall clock time.
Findings: While You.com was on par with the other providers for all four measures, You.com’s Search API far exceeded the others on speed, delivering the same quality at a fraction of the time.

Results Summary
Different query types demand different optimization strategies. Simple factual queries belong in the high-accuracy, low-latency quadrant, while complex research workflows require the high-accuracy, high-latency quadrant. The key is having the flexibility to operate effectively in both.
You.com consistently performs in the optimal quadrants for each query type. For simple factual tasks like those in SimpleQA, we deliver the ideal combination of high accuracy with low latency, exactly where simple queries should be optimized. When we plot accuracy vs. latency and accuracy vs cost, You.com occupies the top-left quadrant that simple factual workflows demand.
And this pattern continues: For freshness, the second component of quality, You.com has the fewest “Can’t answer question” responses while also having the highest F1-score for precision and recall.
Finally, in terms of overall relevance, quality, and confidence, the MS Marco results show You.com’s performance is on par with other Search APIs, but at a vastly faster response time!
- Accuracy: We match or beat alternatives on LLM-augmented QA tasks (SimpleQA, accuracy 77%).
- Freshness: You.com outperforms the market, demonstrating superior ability to surface high-quality, relevant results for time-sensitive queries (FreshQA, F1 = 0.44, Semantic Score = 0.88).
- Latency: Our API consistently responds faster, without compromising quality (p50: 445ms).
- Cost: You.com delivers these results at a lower cost and token usage.
Developers shouldn’t have to trade-off between fast, accurate, or affordable - they should have all three in the right proportion for the task at hand.
What is Possible Today?
Power your AI agents with the most accurate, freshest, and fastest search results at a fraction of the cost. You.com’s Search API gives you the ability to explore what is truly possible:
- Coding Agents: Leverage the Search API to enable coding agents to access the latest code repositories and developer documents.
- Document Search: Harness the Search API for surfacing answers to complex research questions across multiple domains in, for example, legal, regulatory, and tax with accurate citations.
- Workflow Integration: Incorporate this API’s real-time web index into any enterprise agent workflows.
Don’t let your application be limited by slow or shallow retrieval. With You.com, you can deliver smarter, faster, and more capable AI—today.
Subscribe to get a free trial of the Search API including 1,000 API calls. Subscribe and start building here!
LI Test
LI Test
Share Article:
Related resources.

You.com Finance Research API Outperforms Anthropic’s Fable on FinSearchComp T3
July 15, 2026
Blog

The You.com Web Search Eval Harness: Benchmark Any Web Search Provider Yourself
April 21, 2026
Blog

Extreme Single-Agent Inference Scaling for Agentic Search: Achieving SOTA on DeepSearchQA
April 20, 2026
Blog
.png)
Best Web Search APIs for AI Agents: What to Test Before You Commit
April 13, 2026
Blog

Why Your AI Search Evaluation Is Probably Wrong (And How to Fix It)
March 10, 2026
News & Press