Extreme Single-Agent Inference Scaling for Agentic Search: Achieving SOTA on DeepSearchQA
.png)

LI Test
LI Test
AI Agents—systems that combine a large language model's reasoning engine with iterative planning, memory, and tool execution to autonomously achieve goals—are fundamentally shifting how we conduct research and solve complex tasks.
While recent scaling of frontier LLMs has established highly capable baselines for these agents, the primary bottleneck for building systems capable of long-horizon work has shifted from the model itself to the execution environment, commonly known as a harness.
Harness engineering has become increasingly critical. Building robust harnesses that allow for long-horizon inference-time compute—using simple abstractions, powerful tools, and sophisticated context management—gives agent systems the space to dynamically plan, act, and verify their work. These harnesses must be engineered to align with the latent "mental model" of frontier LLMs.
Based on these principles, You.com built a harness specifically optimized for agentic search—a task that demands the high-fidelity synthesis of vast amounts of information—using simple abstractions and capable tools powered by our Search and Contents APIs. This harness powers our Research API, which recently achieved state-of-the-art (SOTA) results on the DeepSearchQA benchmark, scoring 83.67% Accuracy and 93.16% F1 Score on our Frontier variant.
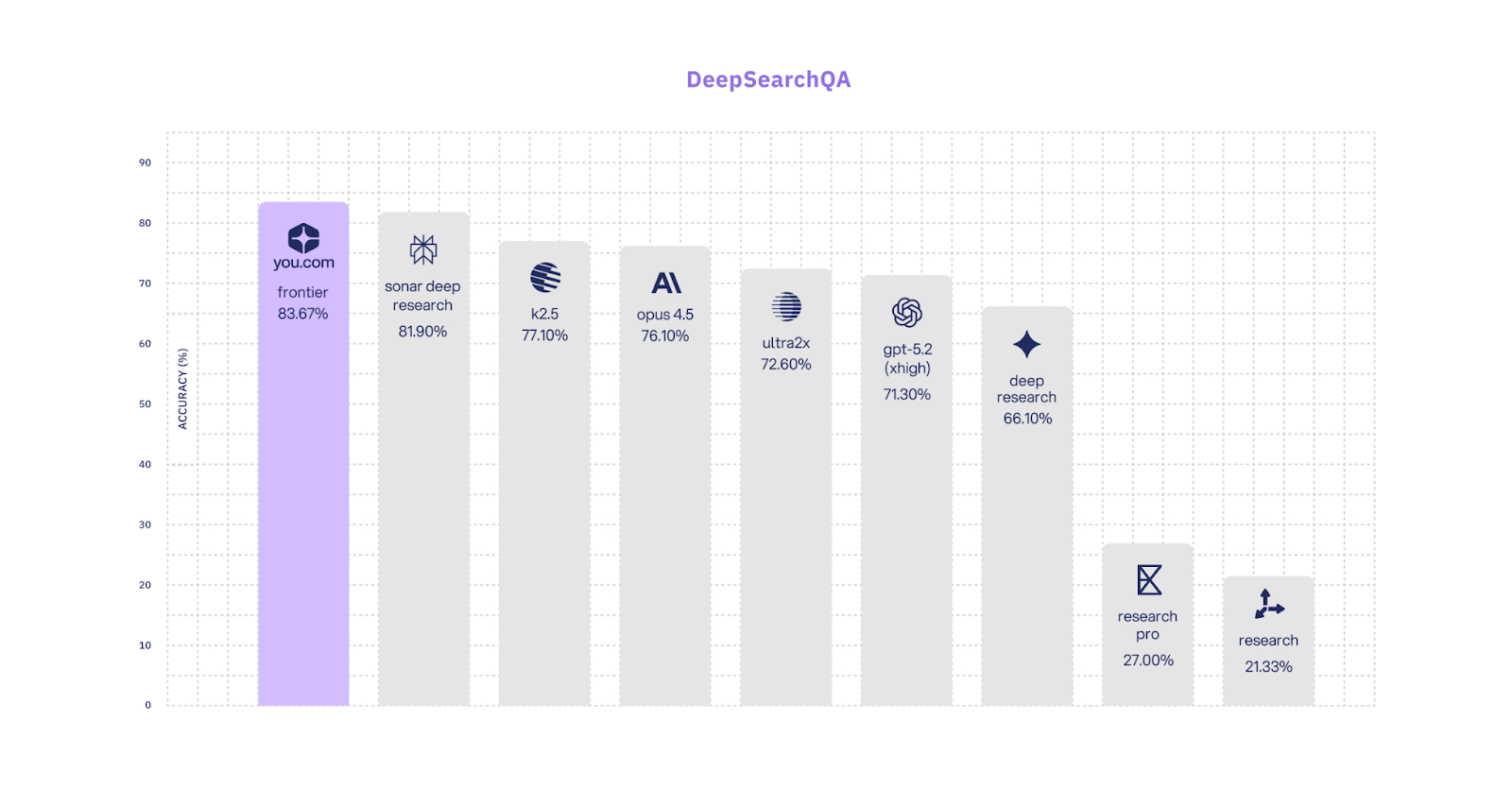
These results were achieved via an architecture optimized for extreme Single-Agent Inference Scaling. Below, we detail the methodology that allows our autonomous search agent to scale to 10 million tokens and up to 1,000 turns in a single session.
The Case for Single-Agent Inference Scaling
Attempting to solve complex benchmarks by orchestrating swarms of agents is a common industry trend. However, recent foundational research from Google DeepMind (Towards a Science of Scaling Agent Systems) demonstrates that on strictly sequential tasks, multi-agent networks can actually degrade performance. Complex tool use and multistep reasoning often incur a "coordination tax," where independent agents amplify errors as mistakes cascade through the execution chain.
When building our harness for the Research API, we experimented with ensemble and multi-agent approaches but found them generally compute-inefficient for agentic search tasks. The result? Multi-agent setups were consistently less accurate than single-agent configurations given the same total compute budget.
Our hypothesis is that as frontier LLMs continue to improve, their latent reasoning capabilities—the emergent ability of high-parameter models to simulate internal logic, iterative planning, and error correction within their neural weights—are increasingly removing the need for fragile multi-agent setups. By focusing on single-agent scaling, we bypass the coordination tax entirely, allowing the LLM to independently manage the execution chain while performing parallel investigation and latent planning effectively.
Budget-Aware Scaling: Incorporating Budget into the Agentic Loop
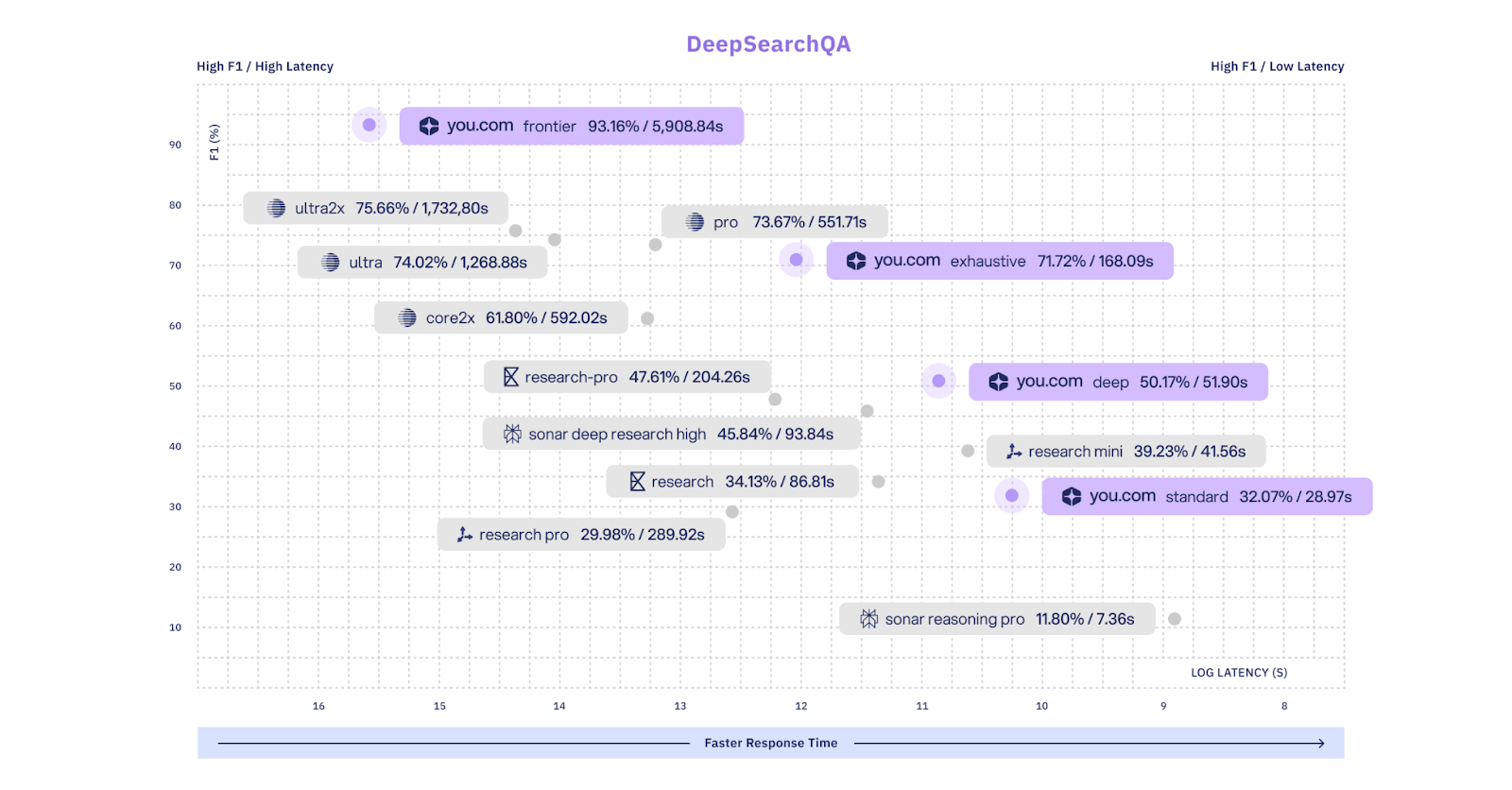
In most open-source agent frameworks, "compute budget" is treated as a passive safety guardrail—a static kill-switch (like max_iterations) that terminates the process once a limit is hit. Because the agent is typically "blind" to this remaining budget, it cannot manage its own research depth. It often relies on a fragile sense of "internal confidence" to stop or simply continues until it hits a context overflow or a hard timeout.
In our harness, budget is a dynamic planning parameter. The agent is aware of its budget from turn zero. This methodology aligns with recent research from Google (Budget-Aware Tool-Use Enables Effective Agent Scaling), which demonstrates that providing agents with a continuous signal of resource availability allows them to internalize constraints and adapt their strategy dynamically.
To achieve this, our harness injects specific <budget> telemetry into the system prompt, instructing the agent to treat the quota as a resource to be fully utilized rather than a limit to be feared:
By making the budget a first-class citizen of the reasoning loop, the agent incorporates these constraints directly into its plan.
Extreme Budget-Scaling: Expending up to 1,000 Turns and 10M Tokens
Treating budget as an elastic scaling parameter allows us to expose a continuous spectrum of compute profiles—from minimal-latency lookups to exhaustive, multi-step research.
This scaling behavior aligns with recent findings published in Anthropic's Claude Opus 4.6 System Card. When evaluating test-time compute on the BrowseComp and DeepSearchQA datasets for Agentic Search, Anthropic observed that for high-complexity tasks, performance improves meaningfully as the token limit per-query is scaled from 1M to 10M tokens.
Similarly, in our highest-compute configuration for DeepSearchQA, the agent autonomously executes up to 1,000 iterations. Like the results seen at Anthropic, we allow a usage budget of up to 10 million tokens per session.
Key Takeaways for Practitioners
As the industry moves from simple retrieval to performing complex, autonomous work using long-horizon AI agents, several engineering principles have emerged for scaling agent performance based on our experiments:
- Prioritise Single-Agent Scaling: For sequential, high-reasoning tasks, focus on scaling a single agent harness. Modern frontier LLMs are increasingly capable of internalizing complex plans within their neural weights; multi-agent hand-offs often introduce more noise and challenges than they solve.
- Budget as a first-class citizen: Don’t treat budget as a hidden guardrail. Making your agents budget-aware allows the model to plan and act dynamically according to live resource usage.
Overcoming the Context Bottleneck
It’s now widely recognized amongst AI researchers and engineers that context management and harness engineering are the defining challenges for building powerful AI Agents. While most frontier LLMs currently support context windows ranging from 200k to 1M tokens, scaling to a 10M-token research task is impossible without sophisticated context management strategies.
In an upcoming technical series, we will dive deeper into other techniques used in our harness:
- Simple Abstractions and Powerful Tools: We equip the frontier models with simple abstractions that they are familiar with: common tools like
searchandweb_fetchwith standard schemas. These tools are powered by our Search and Contents API, and are designed to return accurate token-efficient payloads to the agent. - Masking vs. Compaction: We dive into the memory management techniques used in our harness and share insights on how they allow for long-horizon agentic search
The infrastructure driving these benchmarks is live in production. Engineers can test the impact of inference compute scaling on long-horizon tasks via the You.com Research API Documentation.
(*the SOTA Frontier variant will be released over the next few weeks; contact us for pricing details.)
Featured resources.
.webp)
Paying 10x More After Google’s num=100 Change? Migrate to You.com in Under 10 Minutes
September 18, 2025
Blog

September 2025 API Roundup: Introducing Express & Contents APIs
September 16, 2025
Blog

You.com vs. Microsoft Copilot: How They Compare for Enterprise Teams
September 10, 2025
Blog
All resources.
Browse our complete collection of tools, guides, and expert insights — helping your team turn AI into ROI.
.webp)
What Are AI Search Engines and How Do They Work?
January 29, 2026
Blog

How Richard Socher, Inventor of Prompt Engineering, Built a $1.5B AI Search Company
January 29, 2026
Blog
.jpg)
What Is AI Search Infrastructure?
January 28, 2026
Guides

AI in 2026: Inside the Future-Shaping Predictions from You.com Co-Founders
January 27, 2026
Blog
.webp)
What Is AI Grounding and How Does it Work?
January 26, 2026
Guides

2026 AI Predictions: Insights from You.com Co-Founders
January 23, 2026
Guides
.jpg)
What Is Model Context Protocol (MCP)?
January 22, 2026
Blog
.jpg)
What the Heck Are Vertical Search Indexes?
January 20, 2026
Blog