How do you know if your favorite chatbot, research agent, or AI tool is really better—or if it just happened to perform well on that particular run? Because AI models sample from probability distributions and interact with external systems, the same agent can produce different answers across runs. You.com researchers—Zairah Mustahsan, Abel Lim, Megna Anand, Saahil Jain, Bryan McCann—uncover why a single number can’t tell the full story, and what we should do about it.
Our research has been accepted at two AAAI 2026 workshops. Check out the full paper and open-source code on GitHub.
The Problem: AI Agents Are Unpredictable
Modern AI isn’t just about text generation. Today’s large language models (LLMs) are increasingly acting as agents—autonomously searching the web, solving multi-step problems, and using tools to plan and reason. Evaluating these agentic systems, to ensure they’re completing tasks as designed, is now a cornerstone of AI research and deployment.
But here’s the catch: most benchmarks only report a single accuracy or success rate from one run. This “leaderboard” approach hides a dirty secret—AI agents can be wildly inconsistent from one run to the next. What looks like progress may simply be a lucky streak.
Who cares? Well, if an AI sub-agent is unreliable, your entire system becomes brittle, unpredictable, and potentially unsafe. Imagine choosing an agent for a financial system, a self-driving car, or a medical application, only for it to fail half the time on the same task.
ICC is a Fresh Lens on AI Reliability
To bring transparency and rigor, a group of researchers at You.com proposed a simple but powerful idea: don’t just report accuracy. Instead, report how consistent the agent is—using a metric called the Intraclass Correlation Coefficient (ICC).
What is ICC, and Why Does It Matter?
Originally, the concept of ICC comes from medicine and psychology, where it’s used to measure the reliability of tests and raters.
According to a paper, “Intraclass correlation – A discussion and demonstration of basic features,” published in the National Library of Medicine, “The intra-class correlation coefficient (ICC) is a number, usually found to have a value between 0 and 1…It refers to correlations within a class of data (for example correlations within repeated measurements of weight), rather than to correlations between two different classes of data (for example the correlation between weight and length).”
In AI, ICC answers the question: “If I run this agent on the same question multiple times, do I get the same result?” High ICC means the agent is predictable and stable. Low ICC means its performance is mostly random noise.
Think of two agents, both with 73% accuracy. One has ICC 0.66 (very consistent), the other just 0.30 (inconsistent). Which would you trust in a critical application? The first one. ICC is the tiebreaker that reveals if an AI’s performance is real or just a roll of the dice.
How Stochastic Are Today’s AI Agents? A Deep Dive
To determine the stochasticity—the quality of being random—of AI agents, the You.com research team ran extensive experiments on two popular benchmarks:
- GAIA: Measures agentic reasoning and tool use, with tasks of varying complexity.
- FRAMES: Tests an agent’s ability to retrieve and reason with factual information from multiple documents.
For each task, they didn’t just run the agent once—they ran it up to 64 times per question and measured how much the results varied.
Key Takeaways:
- Agentic evaluations are inherently stochastic. Randomness comes from the model itself, external APIs, and even the task setup.
- ICC varies dramatically by task and agent. On hard, open-ended reasoning tasks (GAIA Level 3), older models like GPT-4o had ICC as low as 0.30 (meaning most “progress” was just noise). Newer models like GPT-5 improved both accuracy and ICC, showing real, reliable gains.
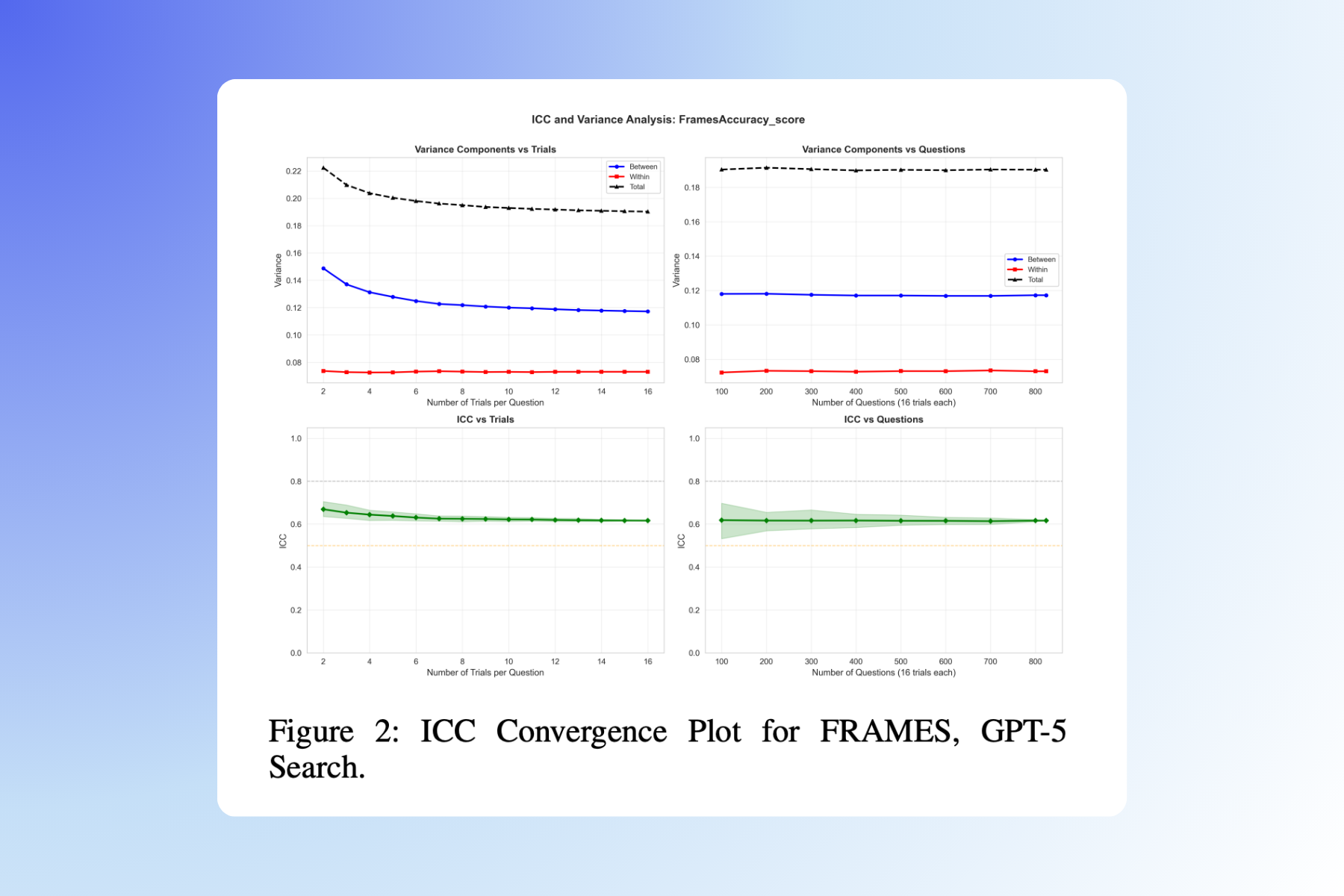
- In information retrieval tasks (FRAMES), ICC was much higher (up to 0.71), meaning results were more stable and meaningful.
- ICC converges quickly. You usually only need 8-16 trials per question for easy tasks— and up to 32 for the hardest ones—to get a trustworthy reliability estimate.
Why Does Stochasticity Matter for Developers and Users?
Single-run leaderboards can be misleading, as they don’t reveal whether an apparent jump in accuracy is genuine or simply the result of chance—something you can only determine by knowing the ICC.
And, because system reliability hinges not just on accuracy but also on consistency, swapping in a new agent with higher accuracy but low ICC can actually make your downstream application much less stable.
The good news is that ICC is actionable. You can proactively boost an agent’s reliability, and therefore its ICC, through better prompting, improved tool design, or smarter system integration, even if the accuracy itself doesn’t change.
Practical Guidelines: How Should the AI Community Evolve?
Our research team recommends that the AI community always report accuracy alongside ICC and within-task variance, ensuring that results are both transparent and meaningful.
To make evaluation practices more standardized and accessible, they also suggest adopting “Evaluation Cards”—much like nutrition labels for AI—that clearly document all key evaluation details, including the task, agent, number of trials, metrics used, and any known limitations.
And, finally, experiments should be designed with scientific rigor rather than as mere leaderboard competitions. This requires running multiple trials, applying proper statistical tests such as McNemar’s test for paired results, and being fully transparent about uncertainty throughout the evaluation process.
Forging the Path to More Trustworthy AI Agents
This research is a call to action: If you care about AI reliability, you need to look beyond single-run scores. ICC gives us the missing piece—visibility into agent consistency and the true meaning of AI performance gains.
By making evaluation stability visible and standardizing how we report results, we can transform agentic AI from an opaque leaderboard race to a trustworthy, scientific discipline. That’s good for developers, users, and everyone relying on AI in real-world systems.
Because we’re looking at AI through a scientific lens, it’s also important to recognize the study’s limitations. The analysis focused on English-language benchmarks and a specific set of agent architectures (mainly OpenAI, Claude, Gemini, and select open-source models), so results may not generalize to other languages or agent types.
Additionally, the ICC approach assumes binary scoring (right/wrong), which means tasks that allow for partial credit or more nuanced grading require further methodological development.
More research is needed to extend these findings to non-English benchmarks, partial-credit tasks, and emerging agent architectures. By acknowledging these boundaries, the AI community can better chart the path toward robust, reliable evaluation practices that serve a truly global and diverse set of users.




.png)







